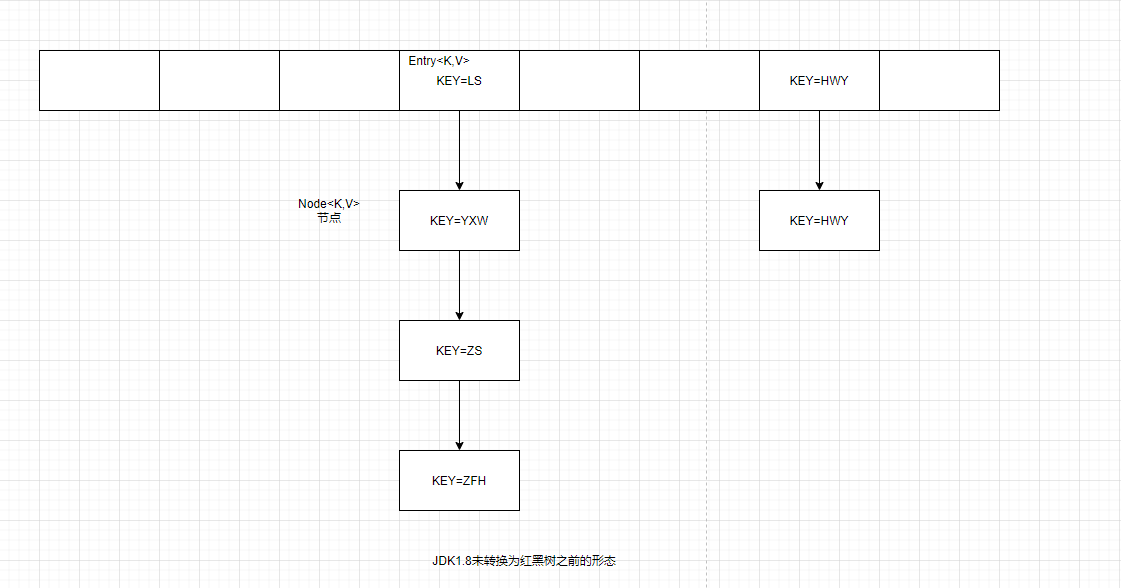
/** * * @param key * @param value * @return */ public V put(K key, V value){ // 通过高16位和低16位的异或运算的到一个hash值 return putVal(hash(key), key, value, false, true); }
/** * 真正的添加元素方法。尾插法 * * @param hash hash for key * @param key the key * @param value the value to put * @param onlyIfAbsent if true, don't change existing value 是否进行元素的替换,用于插入相同key的时候,是否替换值,默认值为false,替换相应的值 * @param evict if false, the table is in creation mode. * @return previous value, or null if none */ final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict){ Node<K,V>[] tab; Node<K,V> p; int n, i; // hashmap的table表的初始化操作,是在这里进行的。第一次执行的时候,会先在这里进行初始化操作 if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length;
/** * Replaces all linked nodes in bin at index for given hash unless * table is too small, in which case resizes instead. 替换指定哈希表的索引桶中所有的连接节点,除非表太小,否则将修改大小 */ finalvoidtreeifyBin(Node<K,V>[] tab, int hash){ int n, index; Node<K,V> e; /* * 如果元素数组为空 或者 数组长度小于 树结构化的最小阈值(MIN_TREEIFY_CAPACITY=64) ,就进行扩容操作.对于这个值可以理解为:如果元素数组长度小于这个值,没有必要去进行结构转换.目的是 * 如果数组很小,那么转红黑树,遍历效率要低一些,这时进行扩容操作,重新计算哈希值,链表的长度有可能就变短了。数据会放入到数组中,这样相对来说效率会高一些 */ if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY) resize(); //如果元素数组长度已经大于等于了 MIN_TREEIFY_CAPACITY,那么就有必要进行结构转换了
// 取出数组对应位置的头节点 elseif ((e = tab[index = (n - 1) & hash]) != null) { //定义几个变量,hd(head)代表头节点,tl代表尾节点(tail) 算法中常用变量 TreeNode<K,V> hd = null, tl = null; do { //先把普通Node节点转成TreeNode类型,并赋值给p TreeNode<K,V> p = replacementTreeNode(e, null); if (tl == null) hd = p; else { p.prev = tl; tl.next = p; } tl = p; } while ((e = e.next) != null);
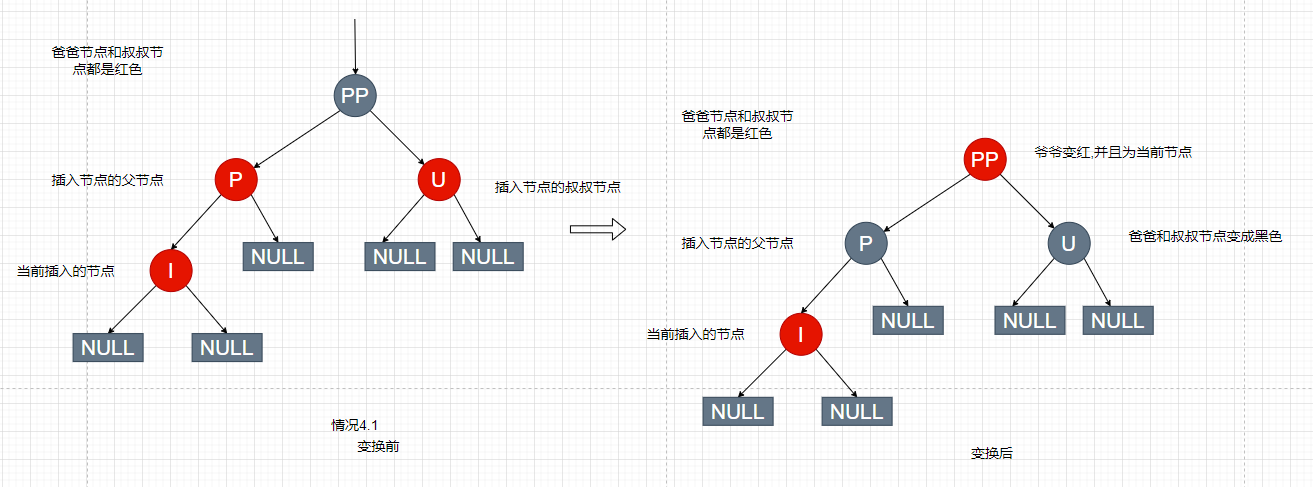
/** * 将树形链表转换为红黑树 */ finalvoidtreeify(Node<K,V>[] tab){ // 定义树的根节点 TreeNode<K,V> root = null; // 遍历链表,x指向当前节点、next指向下一个节点 for (TreeNode<K,V> x = this, next; x != null; x = next) { // 记录x的下一个节点 next = (TreeNode<K,V>)x.next; x.left = x.right = null; // 如果根节点为空,则把当前节点当做根节点。根据红黑树性质,根节点一定为黑色。 if (root == null) { x.parent = null; x.red = false; root = x; } // 根节点已经存在的情况 else { // 取得当前遍历的树形节点的 key 和 hash K k = x.key; int h = x.hash; Class<?> kc = null;
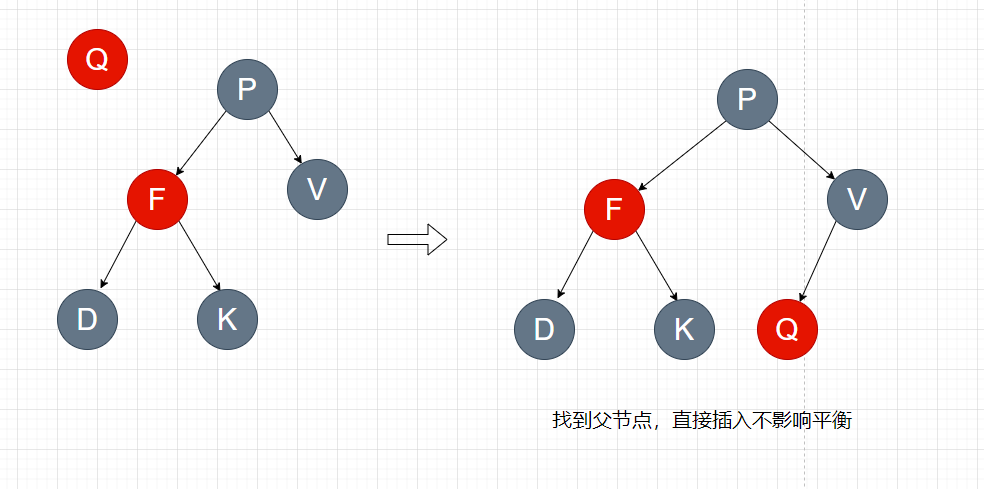
// TODO : 循环开始位置 // 从根节点遍历。这一步主要就是为了判断当前节点应该在树的左侧还是右侧,为节点x找到空位置并插入元素 for (TreeNode<K,V> p = root;;) { // dir代表方向(左边或者右边) ph表示树节点的hash值。 int dir, ph; K pk = p.key;
// 比较hash值大小,判断当前节点插入到左边还是右边,并记录dir的值 if ((ph = p.hash) > h) dir = -1; elseif (ph < h) dir = 1;
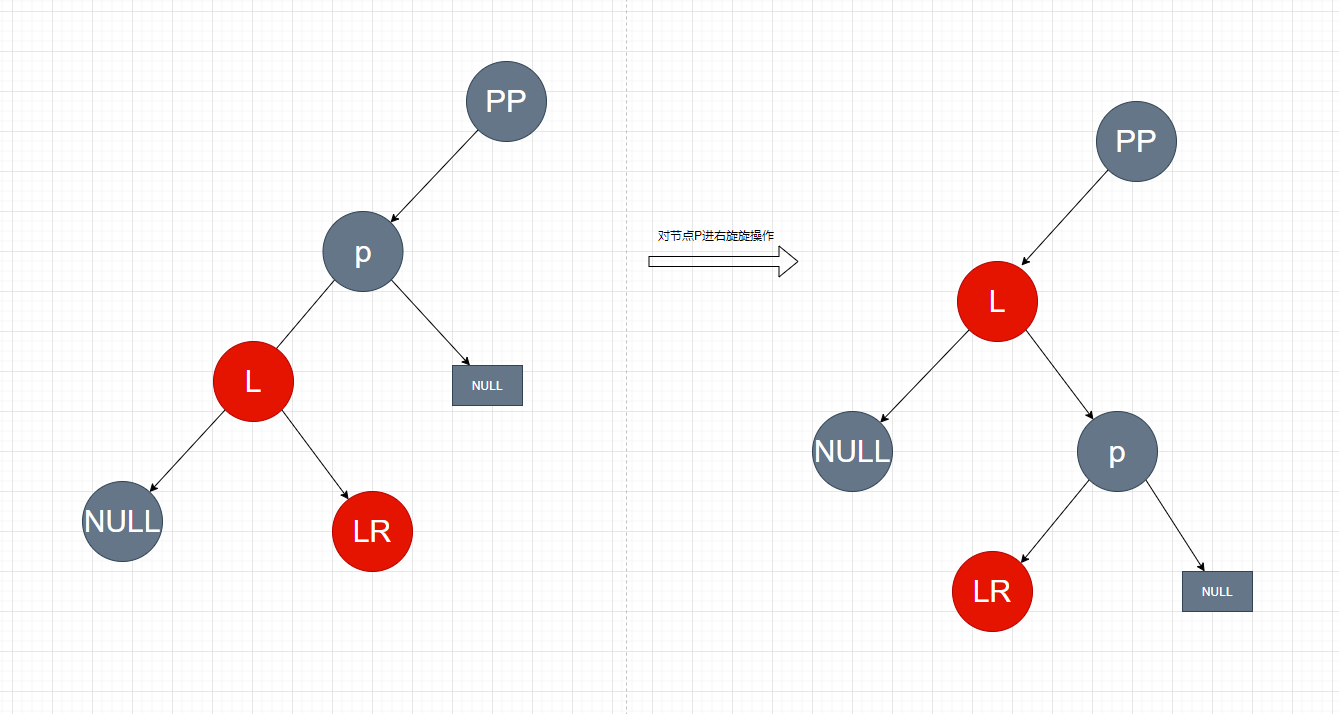
/* ------------------------------------------------------------ */ // Red-black tree methods, all adapted from CLR // 红黑树的左旋的过程 // 1 将节点 p 旋转为其右节点的左节点,即将节点 p 挂到其右节点的左边 // 2 其右节点的左节点成为节点p 的右节点 static <K,V> TreeNode<K,V> rotateLeft(TreeNode<K,V> root, TreeNode<K,V> p){ // r -> 节点 p 的右节点 // rl -> 节点 p 的右节点的左节点 // pp -> 节点 p 的⽗节点 TreeNode<K,V> r, pp, rl;
// p 不为空且右节点不为空 if (p != null && (r = p.right) != null) {
// 1 将 p 的右节点的左节点挂到 p 的右节点,这有两个信息 // a. 断开 p 与其右节点 r 的连接 // b. 因为 p 要挂到其右节点 r 的左边,因此要把节点 r 原来的左节点挂到 p 的右边 if ((rl = p.right = r.left) != null) // r 节点的左节点的⽗节点重置为 p rl.parent = p;
// 2 将 p 的⽗节点设置为 p 的右节点的⽗节点 if ((pp = r.parent = p.parent) == null) // 如果 p 为 root 节点,那么直接将其右节点设置为 root (root = r).red = false; // 3 确定 r 节点应该挂在 p 的⽗节点的左边还是右边。这个根据 p 的位置决定。原来在左边,现在就还在左边 elseif (pp.left == p) pp.left = r; else pp.right = r; // 4 将 p 设置为其右节点的左边 r.left = p; // 5 将 p 的右节点指为其⽗节点 p.parent = r; } // 返回根节点 return root; }
/** * Splits nodes in a tree bin into lower and upper tree bins, * or untreeifies if now too small. Called only from resize; * see above discussion about split bits and indices. * * @param map the map * @param tab the table for recording bin heads * @param index the index of the table being split * @param bit the bit of hash to split on */ finalvoidsplit(HashMap<K,V> map, Node<K,V>[] tab, int index, int bit){ TreeNode<K,V> b = this; // 重新链接到 lo 和 hi 列表,保持顺序 TreeNode<K,V> loHead = null, loTail = null; TreeNode<K,V> hiHead = null, hiTail = null; int lc = 0, hc = 0;
/** * 红⿊树节点仍然保留了 next 引⽤,因此仍可以按链表⽅式遍历红⿊树。下⾯的循环是对红⿊树节点进⾏分组,与普通链表操作类似 * 下面这个循环进行的事链表的分组曹组 */ for (TreeNode<K,V> e = b, next; e != null; e = next) { next = (TreeNode<K,V>)e.next; e.next = null; if ((e.hash & bit) == 0) { if ((e.prev = loTail) == null) loHead = e; else loTail.next = e; loTail = e; ++lc; } else { if ((e.prev = hiTail) == null) hiHead = e; else hiTail.next = e; hiTail = e; ++hc; } } if (loHead != null) { // 如果 loHead 不为空,且链表⻓度⼩于等于 6,则将红⿊树转成链表 if (lc <= UNTREEIFY_THRESHOLD) tab[index] = loHead.untreeify(map); else { tab[index] = loHead; // hiHead == null 时,表明扩容后,所有节点仍在原位置,树结构不变,⽆需重新树化,否则,将 TreeNode 链表重新树化 if (hiHead != null) // (else is already treeified) loHead.treeify(tab); } } if (hiHead != null) { if (hc <= UNTREEIFY_THRESHOLD) tab[index + bit] = hiHead.untreeify(map); else { tab[index + bit] = hiHead; if (loHead != null) hiHead.treeify(tab); } } }
/** * 返回给定目标容量的2次幂大小。 * Returns a power of two size for the given target capacity. */ staticfinalinttableSizeFor(int cap){ int n = cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; }
HashMap <String,Object> hashmap = new HashMap<>(17); cap = 17 int n = cap - 1 = 16; 第一次无符号右移一位 00000000000000000000000000010000 n=16 00000000000000000000000000001000 n >>> 1 ------------------------------------------------------ 0000000000000000000000000001100024 ===>n
第二次无符号右移2位 00000000000000000000000000011000 n=24 00000000000000000000000000000110 n >>> 2 ------------------------------------------------------ 00000000000000000000000000011110 n = 30
第三次无符号右移4位 00000000000000000000000000011110 n = 30 00000000000000000000000000000001 n >>> 4 ------------------------------------------------------ 00000000000000000000000000011111 n = 31
第四次无符号右移8位 00000000000000000000000000011111 n=31 00000000000000000000000000000000 n >>> 8 ------------------------------------------------------- 00000000000000000000000000011111 n=31
001000000000000000000000000000002^30 int n = cap-1; 00011111111111111111111111111111 n=2^30 -1 00001111111111111111111111111111 n >>> 1 ------------------------------------------- 000111111111111111111111111111112^29